
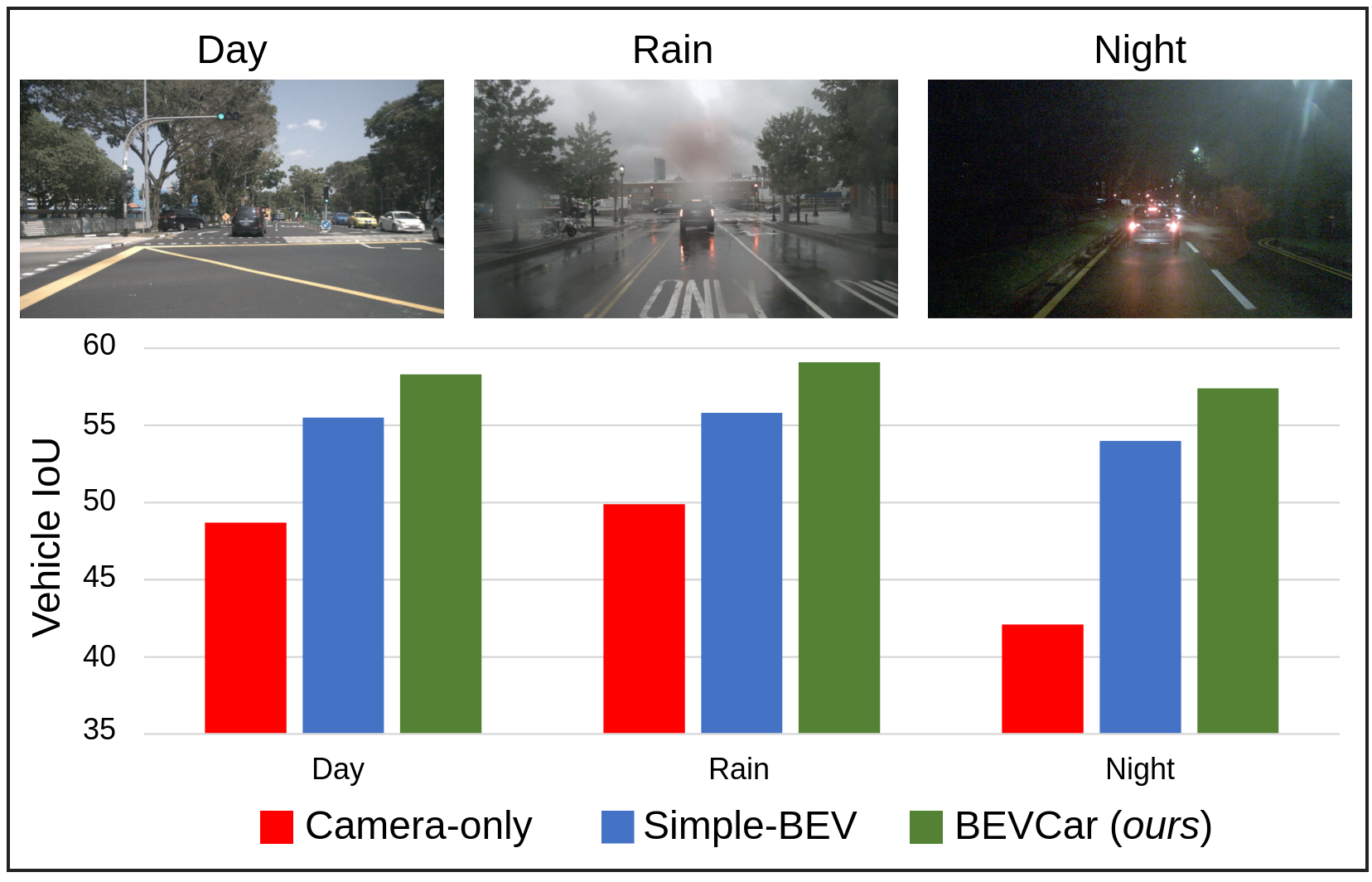
Semantic segmentation of the surroundings from a bird's-eye-view (BEV) perspective can be considered the minimum requirement for holistic scene understanding of mobile robots. Although recent vision-only methods have shown impressive progress in terms of performance, operation under poor illumination conditions such as rain or nighttime remains difficult. While active sensors can address this challenge, the usage of LiDARs remains controversial due to their high cost. Fusing camera data with automotive radars poses a more inexpensive alternative but has received less attention in prior research. In this work, we continue to investigate this promising path by introducing BEVCar for joint map and object BEV segmentation. The core novelty of our approach is to first learn a point-based encoding of the raw radar data and then leverage this representation for efficient initialization of lifting the image features to the BEV space. In extensive experiments, we demonstrate that utilizing radar information significantly increases robustness under poor environmental conditions and improves segmentation for far away objects. To foster future research, we release the utilized weather split on the nuScenes dataset along with our code and trained models in our GitHub repository.







